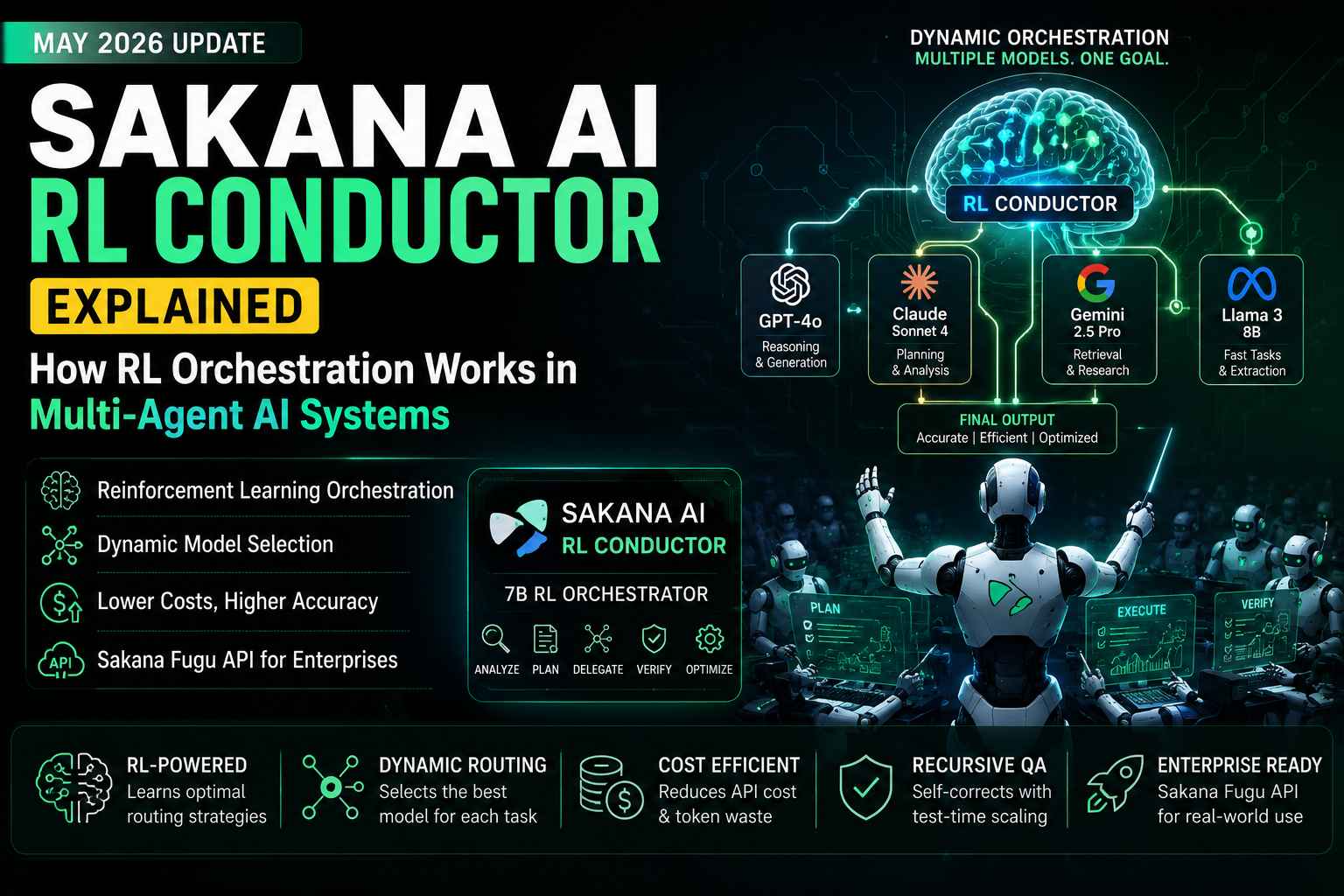
Illustration of Sakana AI's RL Conductor coordinating multiple AI models through reinforcement-learning-based orchestration.
Sakana AI RL Conductor Explained: How RL Orchestration Works in Multi-Agent AI Systems
Last Updated: May 2026
Key Takeaways
- Sakana AI’s RL Conductor is a reinforcement-learning-based orchestration model.
- It dynamically selects and coordinates multiple AI models for complex workflows.
- The system aims to reduce the cost and complexity of traditional multi-agent architectures.
- Sakana Fugu reportedly brings orchestration capabilities into a commercial API product for enterprise deployment.
Table of Contents
- Latest Sakana AI Updates (May 2026)
- Who Created Sakana AI?
- Why Sakana AI Matters in the Post-GPT Era
- The Maturing Reality of Multi-Agent Systems
- What is Sakana’s 7B RL Conductor?
- The Core Innovation: Natural Language Orchestration
- The Power of Reinforcement Learning
- Recursive Test-Time Scaling
- Performance Data & Benchmarks
- Cost vs. ROI Analysis
- What is Sakana Fugu?
- Comparison: RL Conductor vs. Traditional Frameworks
- Systemic Limitations
- Implementation Strategy
- Enterprise Use Cases for RL Orchestration
- The Verdict: Build, Buy, or Monitor?
- Frequently Asked Questions (FAQ)
1. Latest Sakana AI Updates (May 2026)
As the enterprise AI landscape evolves rapidly, Tokyo-based Sakana AI continues to draw preliminary attention. As of May 2026, interest in Sakana AI’s RL Conductor continues to grow across the AI research community. Early industry analysis and public discussions suggest that reinforcement learning–based orchestration may offer a compelling alternative to traditional multi-agent routing systems. Furthermore, public reporting indicates the company has expanded early beta access programs for its commercial orchestration service, Sakana Fugu, catching the eye of engineering teams looking to reduce the overhead associated with static AI agent architecture.
2. Who Created Sakana AI?
Before diving into the technology, it is essential to understand the architects behind it. Sakana AI was founded in Tokyo by two heavyweights of the machine learning world: David Ha (former head of Google Brain Tokyo) and Llion Jones (a co-author of the seminal 2017 paper “Attention Is All You Need,” which introduced the Transformer architecture). The company’s core philosophy revolves around nature-inspired, evolutionary computation. Rather than simply building massive, monolithic models, early reports suggest Sakana AI focuses on creating swarms of smaller, highly efficient models that collaborate—a vision that has now culminated in the development of the RL Conductor.
3. Why Sakana AI Matters in the Post-GPT Era
The artificial intelligence industry is currently dominated by massive foundation models from U.S. tech titans like OpenAI, Google DeepMind, and Anthropic. While latest iterations of GPT, Gemini, and Claude continue to push the boundaries of raw reasoning, the operational bottleneck for enterprises has shifted. The primary challenge is no longer just generating text; it is efficiently orchestrating these heavyweights at scale.
This is exactly where Sakana AI enters the equation. By introducing the RL Conductor, Sakana is pivoting the focus from building larger monolithic models to optimizing how existing models interact. In a post-GPT era, routing every query through a single, expensive frontier model is economically unviable for high-volume enterprise tasks. Sakana’s approach reportedly ensures that whether a system is leveraging Claude for complex coding tasks or Gemini for extensive document analysis, the underlying orchestration layer remains dynamic, cost-effective, and fully automated.
4. The Maturing Reality of Multi-Agent Systems
Let’s start with a blunt industry observation: current multi-agent AI architectures are increasingly showing their limitations in production environments. Over the last three years, companies have invested heavily in building complex agent frameworks. The promise was autonomous productivity. The reality, however, is often a rigid system of static routing nodes that breaks down when user query distributions shift.
Engineering teams have recognized the operational cost of managing these systems. When you deploy a planner agent, an executor agent, and a verifier agent, wiring them together manually creates substantial overhead. This phenomenon, widely characterized as the “swarm tax,” causes API bills to escalate because multiple agents frequently pass massive, redundant context windows back and forth. The system gets confused by edge cases, leading developers to spend critical engineering hours debugging control logic that was supposed to be autonomous. The RL orchestration approach aims to eliminate this operational bottleneck entirely.
5. What is Sakana’s 7B RL Conductor?
The RL Conductor is not designed to be a standalone reasoning engine for end-user chat queries. Instead, it is a highly specialized, 7-billion parameter model trained specifically for management and delegation. It treats standard API endpoints for frontier models as its operational workforce.
When a complex prompt enters the system, the Conductor analyzes the input and autonomously divides the problem into subtasks. It then assigns each subtask to the most appropriate worker model in its available pool. For example, it might identify that Claude Sonnet 4 is optimal for initial architectural planning, Gemini 2.5 Pro is best suited for extensive document retrieval, and a frontier OpenAI model is required for final code optimization.
This represents a significant departure from older semantic routing methods, which typically classify a user’s intent and send the entire prompt to a single, predetermined model. The Conductor builds bespoke communication topologies on the fly.
6. The Core Innovation: Natural Language Orchestration
In enterprise pipeline architecture, inter-agent communication is often the primary failure point. Historically, developers forced large language models to communicate via strict JSON schemas. While reliable for traditional software, this heavily restricts the inherent flexibility of large language models.
Public documentation indicates Sakana AI discovered that the most efficient method for managing language models is through language itself. The RL Conductor coordinates its pool of models using dynamically generated natural language instructions. It executes three primary operations:
- Adaptive Task Delegation: The Conductor acts as an automated prompt engineer, drafting highly specific, contextual instructions tailored to the exact subtask required.
- Dynamic Agent Selection: It evaluates its available pool of models and selects the optimal agent based on task difficulty. Simple data extraction routes to a faster, open-weight 8B model; rigorous mathematical proofs escalate to a heavy-reasoning model.
- Precision Context Management: Instead of injecting the entire conversation history into every agent’s context window, the Conductor defines an “access list.” It curates exactly which past subtasks are relevant to the current agent’s assignment, drastically reducing token bloat.
7. The Power of Reinforcement Learning over Human Intuition
How does a 7-billion parameter model effectively coordinate models significantly larger than itself? The secret lies in Reinforcement Learning (RL).
When engineering teams hardcode frameworks, they limit the system to human cognitive patterns (usually a linear plan-execute-review sequence). During its training phase, the Conductor was provided with complex tasks, a diverse worker pool, and a definitive reward signal tied to the accuracy of the final output. Through iterative RL training, researchers suggest the model discovered which combinations of instructions and agent pairings yielded the highest rewards. It learned to develop highly adaptive routing strategies that are difficult for human engineers to manually design and scale.
8. Recursive Test-Time Scaling: A Strategic Failsafe
One of the most notable features of Sakana’s orchestration is “Recursive Test-Time Scaling.” This concept introduces a critical shift in how compute is allocated during model inference.
In traditional setups, an AI generates an answer and the processing concludes. Sakana’s Conductor, however, has the architectural capability to select itself as a worker in the pool to review the execution pipeline. If an executor model writes a patch and a verifier model flags an issue, the Conductor recognizes the failure state and instantaneously generates a corrective workflow. It dynamically allocates more compute time until the reward criteria are met, acting as a highly effective internal quality assurance loop.
9. Performance Data & Benchmarks
Enterprise adoption requires verifiable data. Preliminary benchmark data indicates notable improvements in complex problem-solving environments when using RL orchestration compared to static baselines.
| Benchmark Evaluation | Legacy MoA Baseline | Sakana 7B RL Conductor |
|---|---|---|
| AIME 2025 (Advanced Mathematics) | 88.2% | 93.3% |
| GPQA-Diamond (Graduate-Level Science) | 83.5% | 87.5% |
| LiveCodeBench (Software Engineering) | 79.8% | 83.9% |
| Overall Task Average | 73.1% | 77.27% |
Note: Benchmark figures are based on publicly discussed research results and early reporting available at the time of writing. Performance may vary depending on implementation details and evaluation methodology.
10. Cost vs. ROI Analysis: Mitigating the “Swarm Tax”
For infrastructure leads, benchmark performance must be weighed against unit economics. A primary vulnerability of agent deployments is unpredictable cost scaling. Unoptimized agents get caught in recursive loops, dragging massive token windows through multiple API calls.
Because the Conductor actively manages the context “access list,” it aggressively prunes the data sent in each API request. It also relies on efficient open-weight models for simpler tasks, reserving premium frontier models exclusively for heavy reasoning. The resulting ROI is clear: enterprises can achieve high-tier accuracy across their application surface while maintaining a significantly lower blended average token rate.
11. What Is Sakana Fugu?
While academic papers outline the underlying research, Sakana AI has reportedly productized this orchestration technology via a commercial service called Sakana Fugu. Early reports suggest it operates as an API endpoint designed to interface seamlessly with existing enterprise infrastructure.
Instead of developers managing disparate API keys for various providers and subsequently maintaining complex routing logic, they simply route prompts to the Fugu endpoint. Fugu handles model selection and orchestration on the backend autonomously. Early public reporting suggests the platform is being evaluated in two primary variants:
- Fugu Mini: Optimized for lower latency applications, relying heavily on hyper-fast open-weight models. Ideal for data extraction and high-volume customer support workflows.
- Fugu Ultra: The comprehensive orchestrator designed for maximum reasoning capability, managing the full spectrum of models. Built for asynchronous, deeply complex workloads like automated codebase refactoring.
12. Comparison: RL Conductor vs. Traditional Frameworks
How does the RL orchestration approach stack up against the highly popular orchestration frameworks currently dominating the market?
| Feature | Sakana RL Conductor | CrewAI | LangGraph | OpenAI Swarm | AutoGen |
|---|---|---|---|---|---|
| Primary Paradigm | RL-Trained LLM Orchestrator | Role-Based Sequential | Stateful Graph-Based | Lightweight Stateless | Conversational Agents |
| Human Workflow Design Required | No | Yes | Yes | Partial | Partial |
| Dynamic Routing | Yes (Autonomous) | Partial (Task-driven) | No (Hardcoded Edges) | Yes (Function-driven) | Partial |
| RL Optimized | Yes | No | No | No | No |
| Agent Selection | Automatic | Manual Assignment | Manual Assignment | Developer Defined | Configured |
13. Systemic Limitations
Shifting from hardcoded logic to RL-driven management introduces distinct risks that engineering leads must mitigate:
- Latency Accumulation: Even with optimized API calls, recursive workflows inherently increase processing time. End-users may experience response delays of 15 to 30 seconds, making this approach less suitable for synchronous, real-time chat interfaces.
- Loss of Granular Control: Organizations trade precise deterministic control for autonomous efficiency. If the system autonomously routes a workload poorly based on unique internal data syntax, teams have limited levers to manually override the “black box.”
- Compliance Hurdles: In highly regulated sectors like finance or healthcare, tracking the exact decision matrix of an autonomous RL model for audit purposes is challenging compared to manual, hardcoded frameworks.
14. Implementation Strategy
If organizational data indicates an infrastructure migration is necessary, a phased approach minimizes operational risk:
- API Efficiency Audit: Measure the exact token expenditure per query in current pipelines to establish a baseline.
- Document Failure States: Catalog the specific inputs that currently cause automated agents to fail or enter infinite loops.
- Sandbox Tiered Routing: Build internal muscle memory by deploying a lightweight classifier to manually route simple tasks to open-weight models before adopting full autonomous orchestration.
- Execute a Shadow Deployment: Mirror a subset of production traffic to the orchestration API and compare execution accuracy, latency, and costs against the legacy system before pushing live to customers.
15. Enterprise Use Cases for RL Orchestration
As organizations move beyond simple chatbots into autonomous operations, RL orchestration opens up several high-value commercial applications:
- Software Development: The orchestration model can autonomously manage codebase refactoring and multi-agent debugging. For instance, the orchestrator can route a problem to an executor agent to write a patch, pass it to a verifier agent for testing, and dynamically redirect the workflow if the verifier detects an edge case failure.
- Customer Support Automation: A dynamic orchestrator can seamlessly route complex technical support queries to heavy reasoning models, while instantly passing simple account balance inquiries to fast, cost-effective open-weight models, drastically reducing the blended API cost of support ticketing.
- Research Workflows: For pharmaceutical or academic research, the system can autonomously coordinate literature reviews, extracting data from massive context windows across disparate proprietary models to synthesize a final, highly accurate report.
- Financial Analysis: Quantitative teams can utilize RL orchestration to process quarterly earnings, assigning one agent to parse regulatory filings and another to run statistical models, allowing the orchestrator to format a comprehensive brief for human analysts.
- Knowledge Management: Large enterprises can orchestrate internal search and document retrieval, assigning agents to navigate specific siloes of company data (like HR policies versus technical documentation) and unifying the findings into a coherent response.
Sakana AI’s RL Conductor introduces a reinforcement-learning approach to AI orchestration that could reduce routing complexity, lower infrastructure costs, and improve multi-model coordination. While still evolving, it highlights a broader industry shift from hardcoded agent pipelines toward adaptive orchestration systems.
16. The Verdict: Build, Buy, or Monitor?
The viability of manual, graph-based agent orchestration is narrowing. Forcing human-designed sequence logic onto advanced neural networks creates unnecessary friction and fragility at scale. Utilizing natural language via RL orchestration provides a much more resilient, adaptable alternative.
If your engineering team is actively struggling with the brittleness and escalating API costs of current agentic frameworks, monitoring commercial endpoints like Sakana Fugu is a sound strategic move. Early reporting suggests it represents a streamlined method for accessing the collective capabilities of the industry’s best frontier and open-weight models without the crushing management overhead.
17. Frequently Asked Questions (FAQ)
1. What is Sakana AI?
Sakana AI is a Tokyo-based artificial intelligence research company focused on creating efficient, nature-inspired foundation models. It emphasizes collective intelligence (swarms) over single, massive monolithic models.
2. Who founded Sakana AI?
The company was founded by David Ha, former head of Google Brain Tokyo, and Llion Jones, a co-author of the landmark “Attention Is All You Need” paper that introduced the Transformer architecture.
3. What is the Sakana RL Conductor?
The RL Conductor is a 7-billion parameter language model trained via reinforcement learning to autonomously orchestrate, manage, and delegate tasks to a dynamic pool of other foundation models.
4. What is Sakana Fugu?
Sakana Fugu is reportedly the commercialized API product of the RL Conductor research. It allows enterprise developers to route prompts to a single endpoint, which then handles model selection, context management, and orchestration autonomously.
5. How does RL orchestration work?
Instead of using static, hardcoded logic to connect AI agents, RL orchestration uses a central AI model that has learned through trial and error how to write natural language instructions and route tasks to the best available models dynamically.
6. How is the RL Conductor trained?
It is trained using end-to-end reward maximization. The model is given complex tasks and a worker pool, receiving reward signals based on the accuracy and formatting of the final output to teach it optimal delegation strategies.
7. What benchmarks does the RL Conductor outperform?
In early testing, it achieved 93.3% on AIME 2025 (Advanced Math), 87.5% on GPQA-Diamond, and 83.9% on LiveCodeBench, consistently outperforming legacy Mixture-of-Agents (MoA) baselines.
8. Can RL Conductor replace CrewAI or LangGraph?
RL Conductor represents a fundamentally different orchestration philosophy from CrewAI and LangGraph. While it may reduce the need for manually designed workflows in some environments, many organizations will continue using traditional frameworks where deterministic control, auditability, or custom business logic are required.
9. What are the limitations of this system?
The primary limitations include increased latency due to recursive test-time scaling, a loss of granular deterministic control for developers, and potential compliance issues in regulated industries due to its “black box” routing decisions.
10. Should enterprises adopt Sakana Fugu?
Enterprises dealing with high API costs, frequent edge-case failures in their current agent frameworks, and complex asynchronous workloads should closely monitor early reporting on Sakana Fugu to evaluate if it can streamline their operations.






